
In December, we released a new version of Ironforge. This new version was the first step towards providing a robust framework for observability, incident management, and high availability. Today, we are excited to announce new analytics and logging features that will help you better understand your RPC traffic and improve your application's performance and reliability, along with other improvements.
Additionally, following our renewed focus, we have discontinued the last batch of legacy features that were still available in Ironforge. We are confident that this will allow us to focus on the features that matter most to you.
Logs
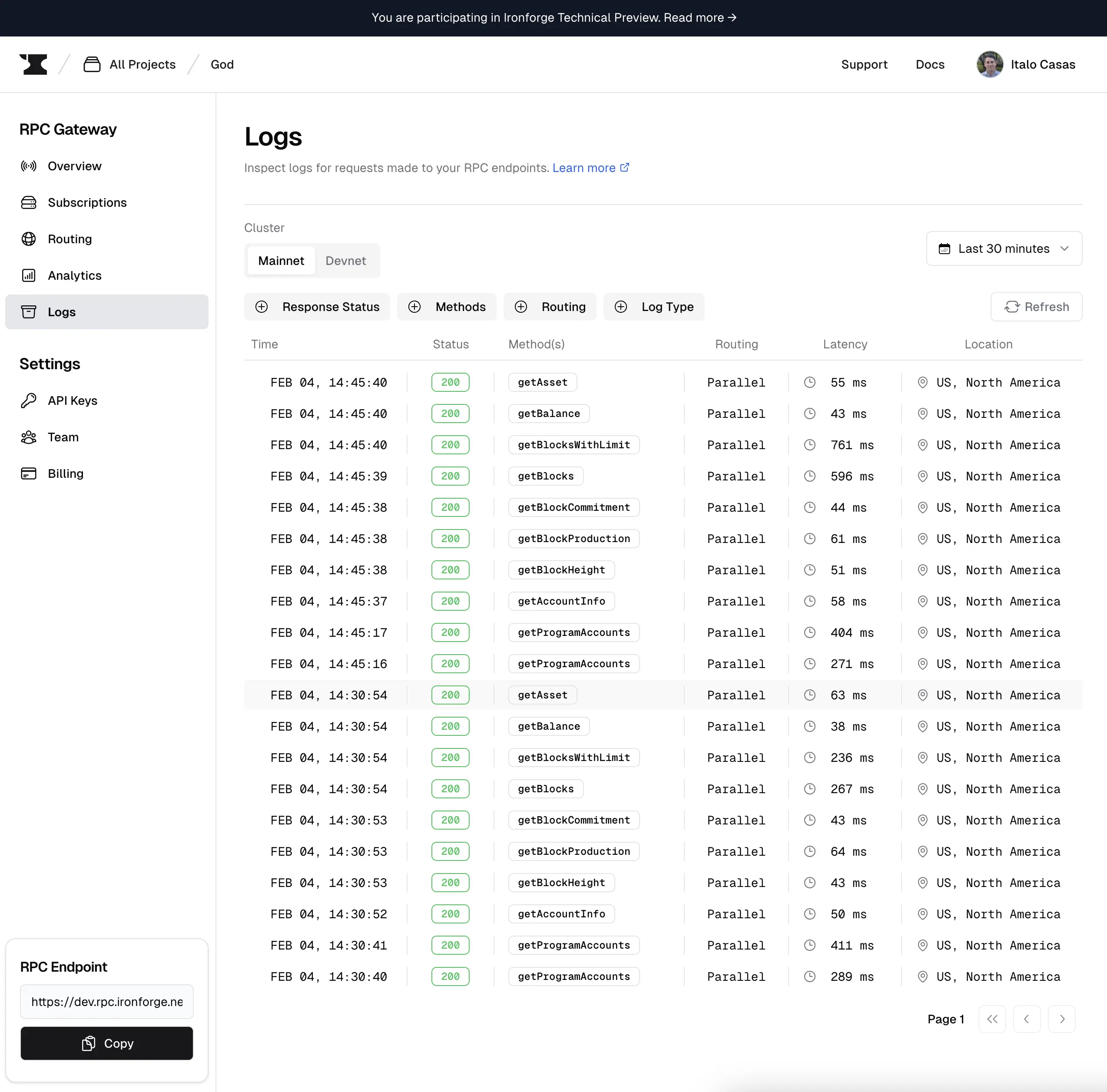
Starting now in Ironfroge you can see not only logs for every request but also you can track the performance of every RPC Endpoint that was called. This is a great feature to understand how your RPC Endpoints are performing and how you can improve them.
Main View
Details
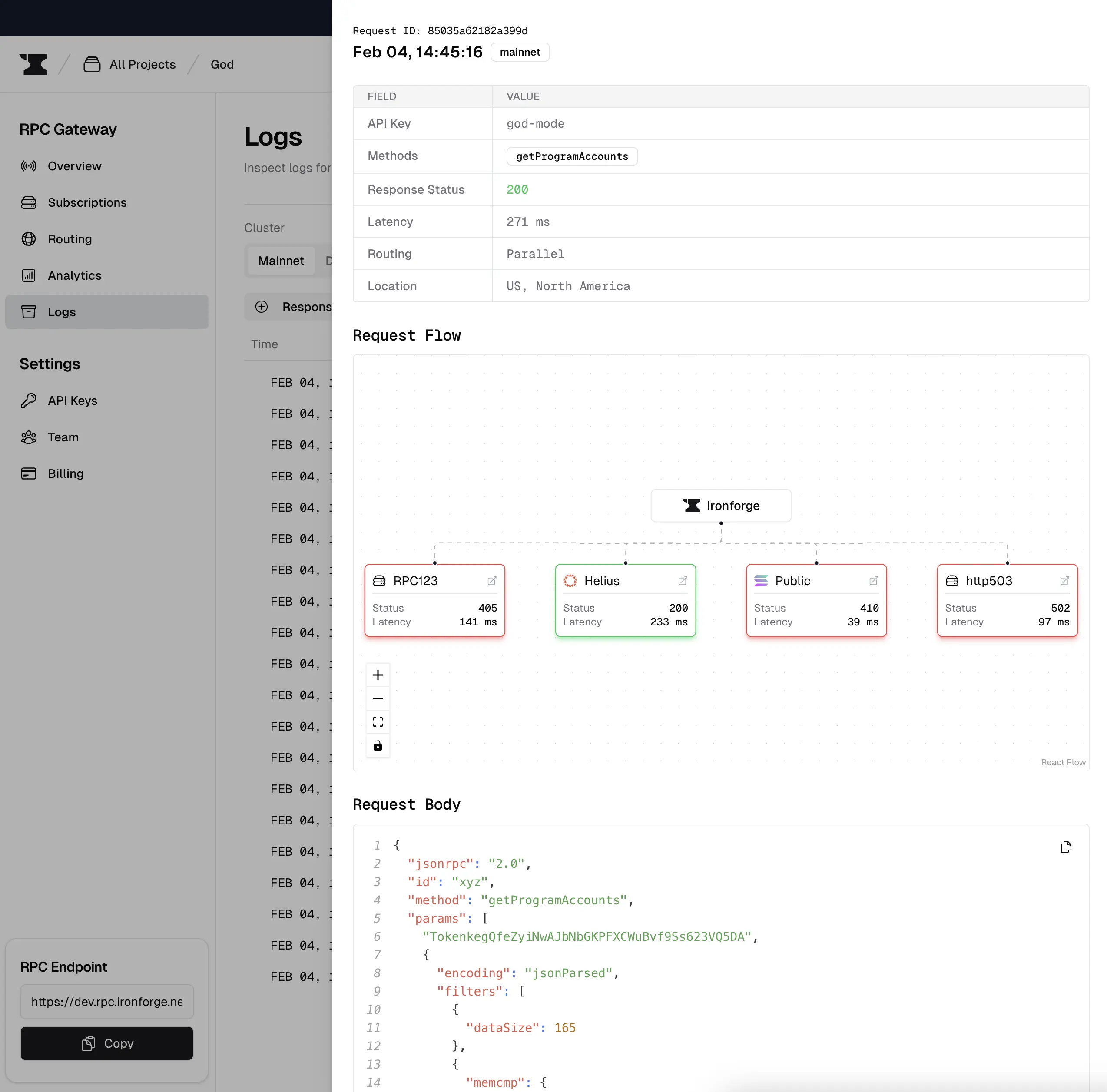
In addition to this, we released many other features. For example, you can now see the end-to-end latency, which includes Ironforge latency overhead.
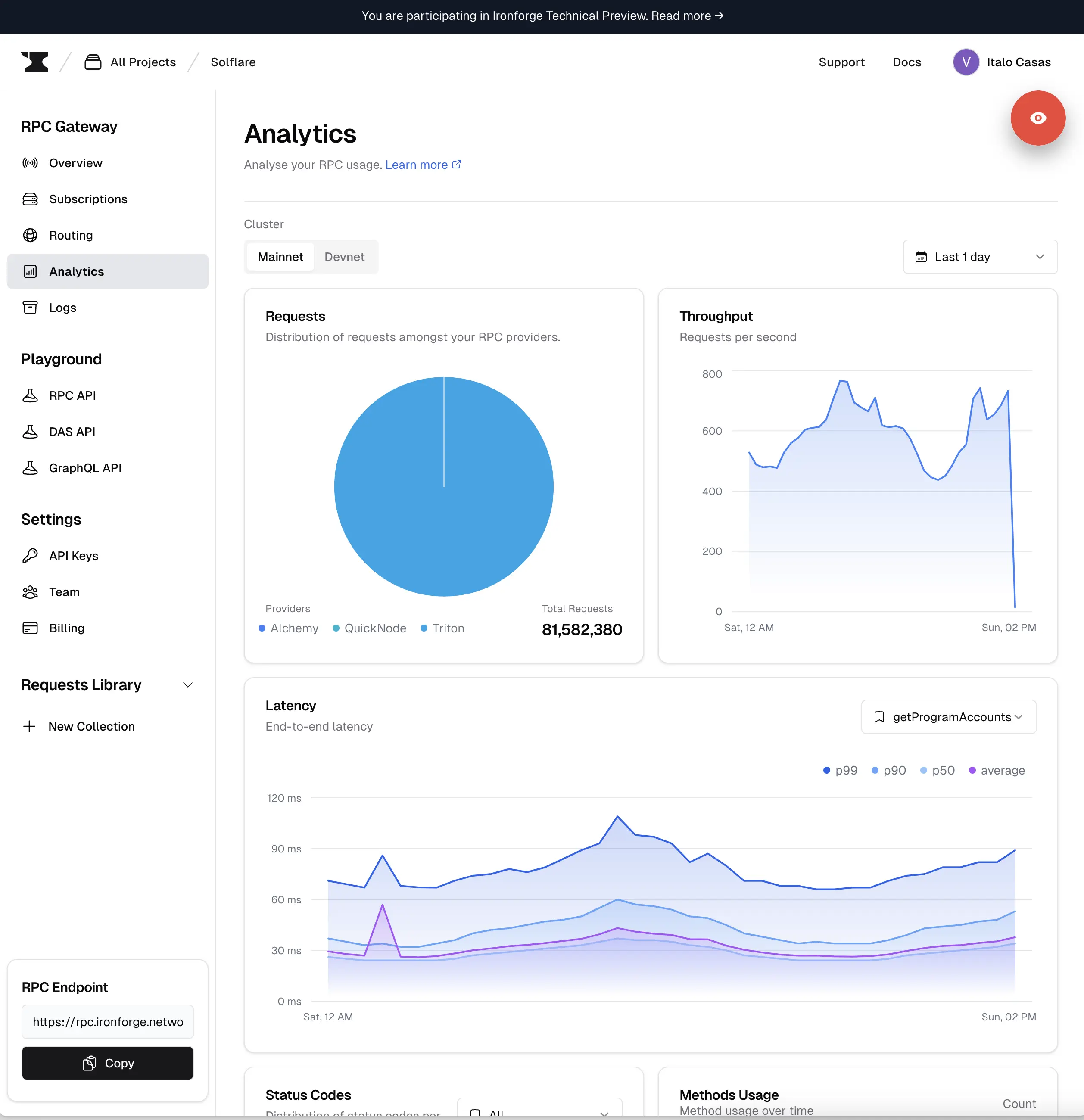
Analytics
We also released new analytics metrics and improved some of the existing ones based on your feedback.
To highlight three of the new metrics that we released:
- Improved latency graph with the inclusion of avg, p50, p90, and p99.
- New graph for the request distribution to RPC endpoints.
- New graph for request per second
Routing
Our previusly released Round Robin routing algorithm is now named "Sequential". This change was made to better reflect the behavior of this algorithm. We are working in releasing a new routing algorithm in the next few weeks. Stay tunned.
Performance and reliability improvements
After just 5 weeks, Ironforge is processing more than 10 million RPC requests every hour (on a normal day without any on-chain event), and our number of requests is growing by around 50% every week so far. Due to this sudden and explosive growth, some parts of our systems had to be re-architected to support this and our future growth.
Additionally, we took this opportunity to improve our failover mechanisms to minimize the risk of experiencing downtime incidents. We also enhanced our monitoring and alerting systems to detect and respond to any incidents more quickly.
What's next?
For February, we are working on a new routing algorithm and a more dynamic routing configuration. We are also working on improving the experience around Organization, Teams, and Projects.
If you want to stay updated with our progress, you can follow us on Twitter